


学習進度を反映した割引率の調整
概要
一般的な強化学習では,強化信号をできるだけ大きくするために, 割引率 を 1 に近い固定値にすることが多い.しかし, 割引率を 1 に近づけすぎると収束が遅くなるため, 割引率のチューニングは重要かつ困難な問題である.
一方,学習は,内部モデル(いわゆる世界像)を学習者の内部に作り上げていく過程とみなせるが, 学習初期段階ではこの内部モデルの構築が不十分である.したがって, 将来の報酬の予測は困難であり,予測値の信頼性は著しく低下する. そのような状況下で遠い将来の報酬を目先の報酬と同等に評価することは無意味だと思われる. すなわち,従来法のように割引率を 1 に近い値に固定し続けることは必ずしも適切な戦略とはいえない. むしろ,とりあえず目先の報酬を確保しておくような予測戦略の方が望ましい可能性がある.
よって,「学習進度が浅いときには割引率を下げて即時報酬を重視し, 学習が進むにつれて次第に割引率を大きくして, 将来の報酬も考慮していく」という戦略が有効でないかと考えられる. 本研究ではこの仮説を検証し, 学習初期に割引率を下げることによって学習性能が向上することを数値実験により確認した. 特に,学習進度の指標として信頼度と呼ばれる値を用いることが効果的であることがわかった.
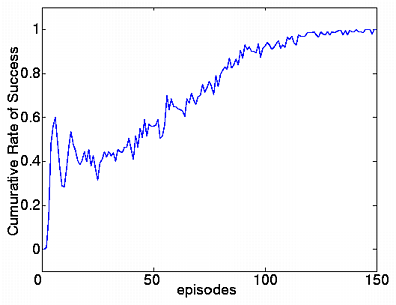
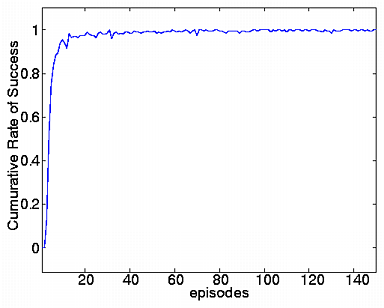
20 エピソードごとの成功率.左:従来手法,右:提案手法
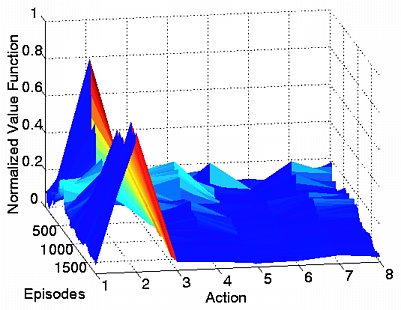
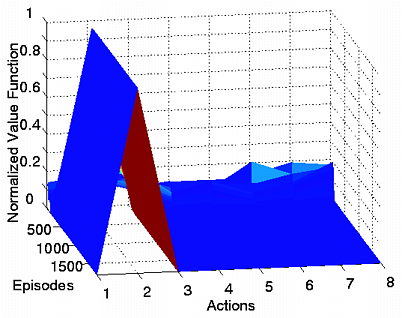
ゴール付近の行動価値関数の推移.左:従来手法,右:提案手法
参考文献
- 尾川順子,並木明夫,石川正俊:学習進度を反映した割引率の調整, 電子情報通信学会ニューロコンピューティング研究会 (札幌,2003.2.4)/電子情報通信学会技術研究報告, NC2002-129, pp.73-78 [PDF (1.2M)]