


Targeted modeling for dynamic background subtraction in high-speed sequences
Summary
When observing the world at framerates vastly exceeding the capabilities of the human eye, applications with super-human capabilities become possible. However, with increasing framerate, the computational demand increases as well. If however interesting regions in the image are first located, more sophisticated processing can be subsequently applied to only these parts. If looking at the problem from the opposite side, high-speed sequences can help us better understand what is going on in the scene.In this research we address the two aspects above, and propose a background subtraction algorithm that is able to locate regions of interest at nearly 1000 fps while at the same time exploiting the extra information available between frames of normal cameras to generate superior background subtractions.
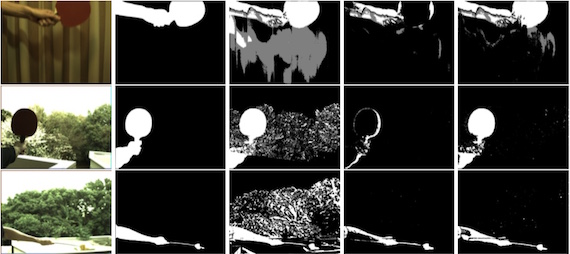
The purpose of a background subtraction algorithm is to identify which pixels of the image, i.e. which parts of the scene, that are changing, typically caused by moving objects. However, one complicating factor is that shadows caused by the moving objects will fall on the background and might be wrongly treated as foreground. There are methods to detect if a pixel is shadow rather than foreground (Prati et al. CVPR'99) which essentially defines a shadow as a darker, but not too dark, version of the background color. Thus, if the intensity differs too much, the pixel will be classified as foreground. If the shadow is detected at an early stage however, we can learn that the pixel in question is subject to a moving shadow and as the shadow gets darker we can adapt.
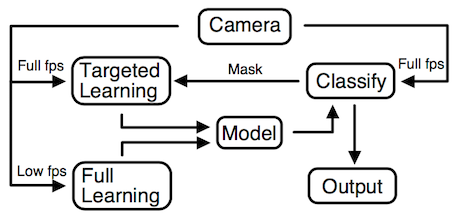 |
In the algorithm a background model is attached to each pixel. This model is a Gaussian Mixture Model over the HSV color space with a variable number of components. A pixel is considered to be part of the model if the probability of the pixel given the model is greater than some constant. The model is updated through two cycles, one running at regular framerates and one running at high framerates. The former update cycle updates the model for all pixels in the image while the contribution of this research is on the latter update cycle. In this the image is classified using the current model. Given the classification a targeted model update is performed on pixels with certain properties: 1) pixels that have been classified as shadow and 2) pixels that is classified as foreground, but whose neighbors would have classified the pixel as background. 1) will introduce shadow intensities in the model thus helping the model to classify shadows as background before they are classified as foreground. 2) targets cases with periodic background motion, such as leaves in a tree or waves.
 |
References
- Nils Stål, Niklas Bergström, Masatoshi Ishikawa: Exploiting High-Speed Sequences for Background Subtraction, 3rd Asian Conference on Pattern Recognition ACPR2015) (Kuala Lumpur, Malaysia, 2015.11.3-6)